Advanced RAG System Design: Complete Guide to RAG Patterns, Accuracy Techniques, and Modern RAG Pipelines

Advanced RAG System Design
RAG systems help AI use your real data, but basic RAG often fails when queries are unclear, files are messy, or retrieval returns the wrong information. This article introduces the key advanced RAG techniques:Query Rewriting, CRAG, Ranking, and HyDE, that make RAG more accurate, reliable, and ready for real-world use. By learning these patterns, you’ll understand how to design stronger, smarter RAG pipelines that reduce hallucinations and deliver trustworthy answers.
1. Basic RAG Pipeline
Retrieval-Augmented Generation (RAG) solves one simple problem is “LLMs don’t know your data, RAG brings your data into the LLM’s reasoning”. Before learning advanced RAG patterns, you must deeply understand the basic RAG pipeline, because every advanced technique builds on these same steps.
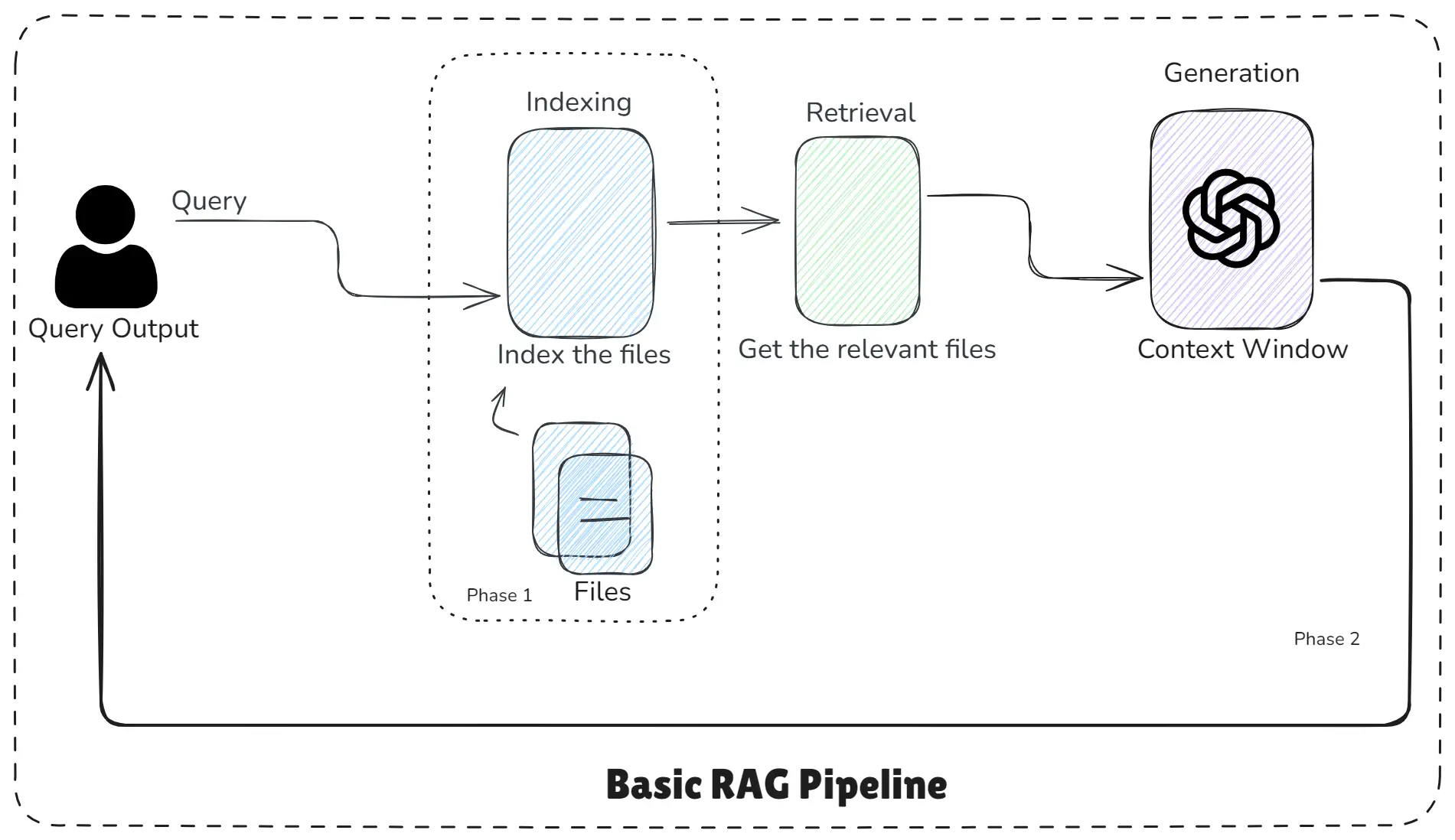
Basic RAG Pipeline
This image “Basic RAG Pipeline” clearly shows the three core phases of a Basic RAG pipeline:
- Indexing
- Retrieval
- Generation
The flow from User Query → Indexing → Retrieval → Generation → Final Output is easy to understand and visually clean and click to Introduction to RAG for better understanding of “RAG System Design: Advanced RAG Patterns & Advanced Rag Pipeline”.
How Basic RAG Works?
This RAG pipeline work flow is step-by-step according to the diagram.
Step 1: Indexing - Preparing Your Data for AI
RAG always begins with indexing, which means:
- Splitting documents into chunks
- Creating embeddings
- Storing embeddings inside a vector database
This is like converting your files into a searchable, numerical library and without indexing, retrieval is impossible.
Think of indexing as building an intelligent map of your data.
Step 2: Retrieval - Finding the Most Relevant Chunks
When the user asks a question, the system:
- Converts the query into an embedding
- Searches the vector database
- Returns the most relevant chunks
This step is the heart of RAG, and it determines how accurate your final answer will be.
If retrieval fails, the entire RAG pipeline fails.
Step 3: Generation - LLM Uses Retrieved Chunks to Answer
The selected chunks are added to the context window of the model.
Now the LLM can generate:
- factual
- grounded
- context-aware
- hallucination-resistant
answers. It no longer guesses, it reads your data.
2. Why Improve RAG Accuracy?
When we talk about building a RAG system, most people think accuracy only depends on the AI model but that’s not true.
The biggest reason to improve RAG accuracy is simple:
Even if your system is fast or cheap, it becomes useless if the answers are wrong.
This image explains this perfectly using two real, everyday mistakes:
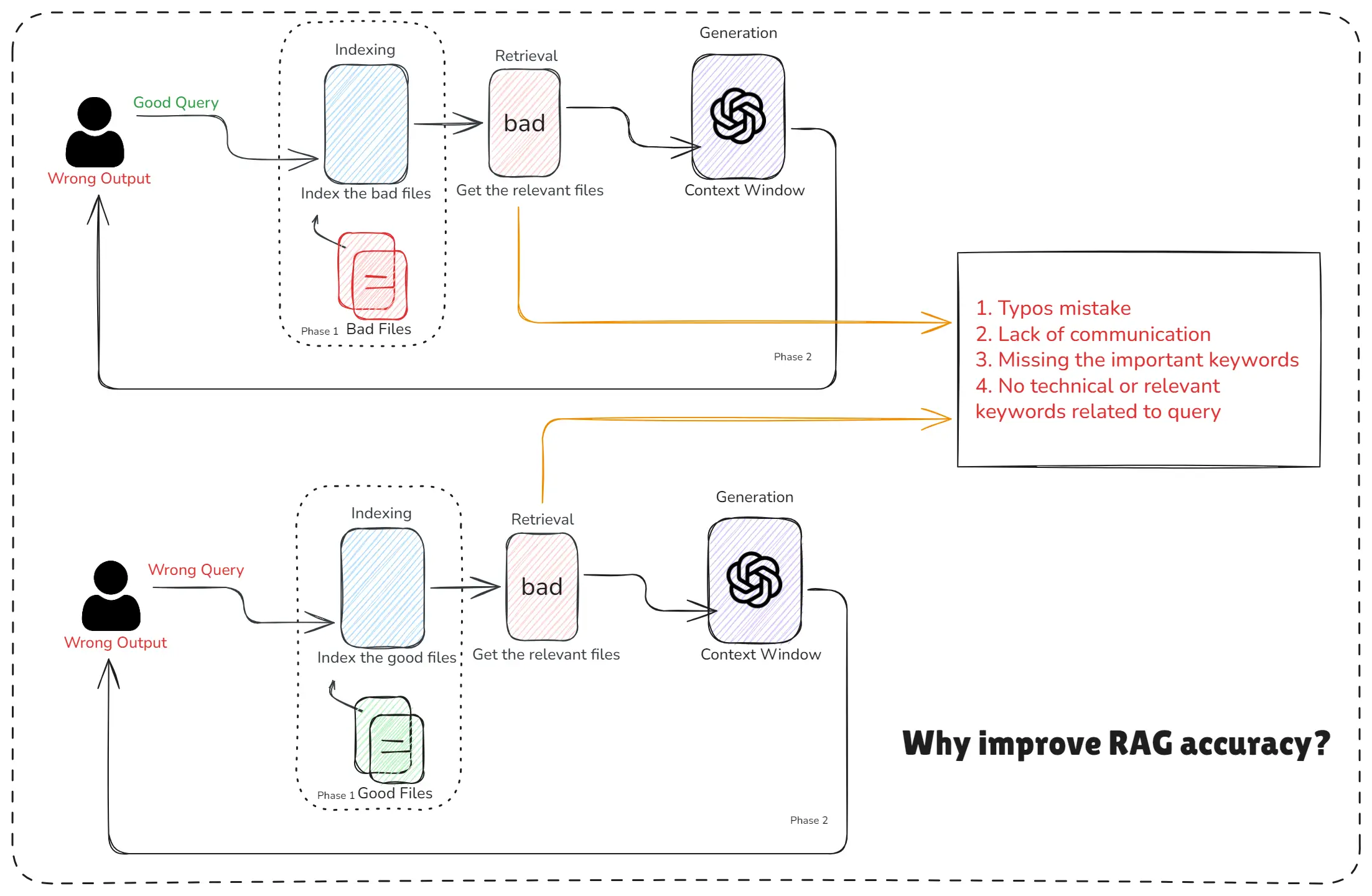
Why Improve RAG Accuracy
1. Wrong Files Indexed = Wrong Answers
Even if the user asks a good query, the output will still be wrong if:
- The uploaded documents were incorrect
- Files were indexed with mistakes
- Wrong versions of files were used
This means the RAG system is pulling information from the wrong sources, and the AI cannot magically fix that.
Bad data = Bad output. Good query + bad files = wrong answer.
2. Wrong Query = Wrong Answers
Even if the files are perfect, the user can still reduce accuracy by:
- Making typos
- Asking unclear questions
- Missing important keywords
- Using vague or non-technical terms
This RAG diagram shows a relatable scenario:
Good files + bad query = wrong answer.
The model retrieves irrelevant chunks because the query itself is unclear.
3. We Cannot Control the User, This Makes Accuracy Even More Important
We cannot force users:
- To write perfect queries
- To upload clean data
- To use the correct keywords
This is a real, practical limitation in every RAG system.
Because we cannot control users, the system must be designed to be accuracy-friendly by default.
That’s exactly why improving accuracy matters so much.
4. In Real Life, Accuracy Matters More Than Speed or Cost
A RAG system is usually used for Business documents, Policies, Legal text, Medical knowledge, IT documentation, enterprise workflows, and so on.
In these use cases:
- A wrong answer can cause damage.
- A slow or expensive answer rarely causes problems.
So accuracy always wins over: Speed, Cost, and Token optimization
Fast but wrong = useless and Slow but correct = useful.
3. Two Important Questions
Before jumping into advanced RAG systems, let’s answer the two core questions shown in the diagram “Why improve RAG accuracy?” . These questions reveal why accuracy is the most important part of any RAG pipeline.
Question 1
Suppose we have four RAG systems with different levels of speed, accuracy, and cost. Which one should we choose?
Answers is the best choice is Accuracy, because even if a system is fast or cheap, it’s not useful if the answers are wrong.
Speed and cost matter but accuracy decides whether your system is trustworthy. No user cares about fast wrong answers.
Question 2
How can we control accuracy?
Most people believe accuracy depends only on the AI model, but this diagram proves that’s not true. RAG accuracy can break for several real reasons:
- If the source files are wrong, the output will also be wrong.
- If the files are correct but the user has little knowledge, they may ask a poor or incomplete query.
- If the user forgets important keywords or makes many typos, accuracy will drop.
So, instead of only doubting your pipeline, think from the user’s perspective:
- The files they uploaded might be indexed incorrectly.
- The user’s query might be unclear or incorrect.
- The user might introduce too many typos.
Accuracy prevents hallucinations
Even the best LLM will hallucinate if:
- Retrieval returns wrong chunks
- Context is missing
- Query is unclearImproving accuracy ensures the model stays grounded in real documents.
⚠️ Note: We cannot fully control user queries or their files.
That’s why the next big question is “How can we design RAG systems to be more accuracy-friendly despite these issues?”
4. Query Rewriting / Translation in RAG
Query Rewriting is an advanced RAG technique that improves retrieval accuracy by cleaning, expanding, and correcting the user's original query before it goes into the RAG pipeline.
Most users:
- Write incomplete questions
- Forget important keywords
- Add typos
- Ask vague queries
Because of this, retrieval often brings back irrelevant or weak chunks, leading to poor answers.
Query rewriting fixes this problem.
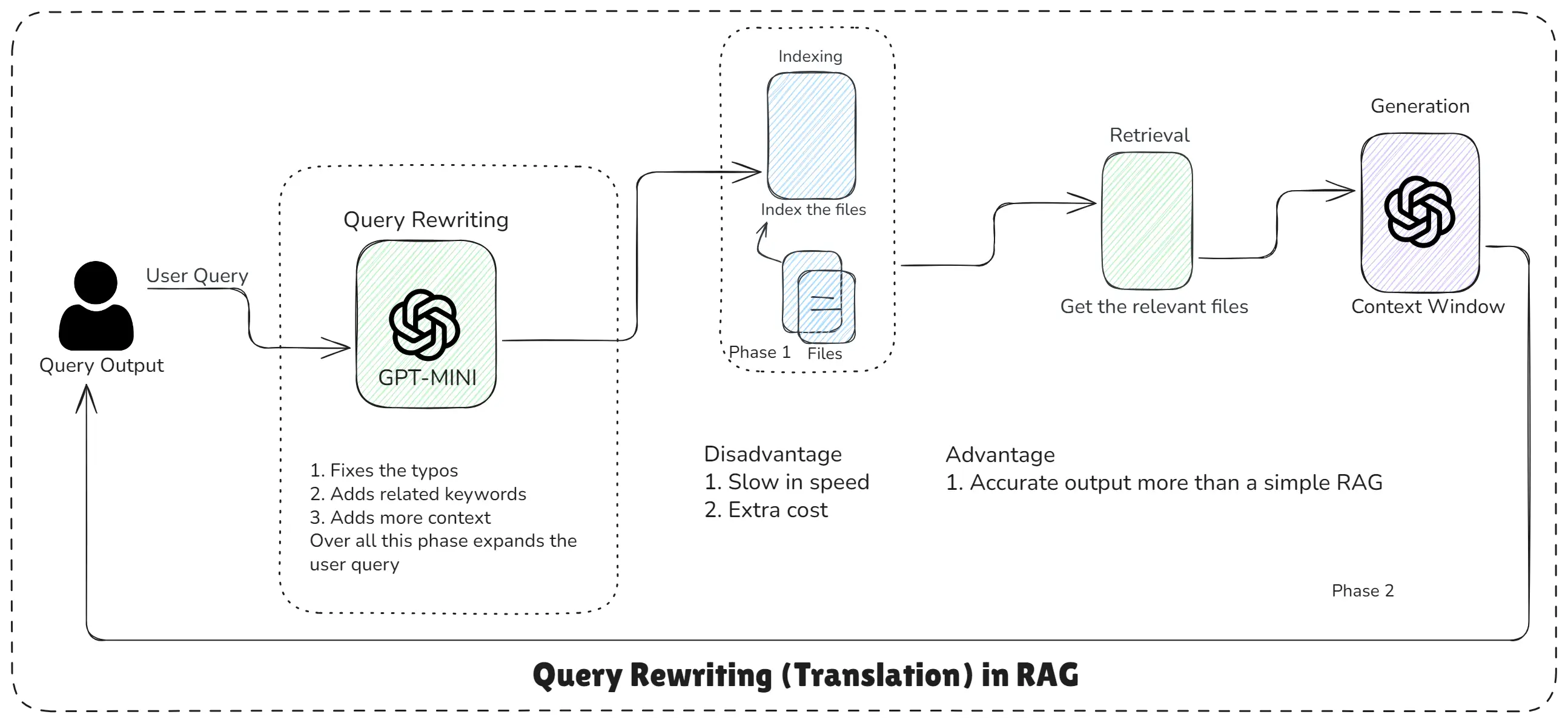
Query Rewriting (Translation) in RAG
Query Rewriting is a step where a smaller or cheaper LLM (like GPT-Mini) takes the user’s raw query and transforms it into a:
- Corrects mistakes
- Adds keywords
- Includes missing context
- Boosts semantic search accuracy
version of the same question and even though it adds a small cost, it dramatically improves the quality of your RAG system.
Query Rewriting vs No Rewriting
| Without Query Rewriting | With Query Rewriting |
|---|---|
| Typos break semantic search | Typos are fixed |
| Missing keywords reduce relevance | Important keywords are added |
| Vague queries confuse retrieval | Missing context is filled in |
| Retrieval returns wrong or weak chunks | Retrieval accuracy increases |
| Leads to poor RAG performance | Even simple rewriting significantly boosts RAG accuracy |
The goal is make the query easier for the vector database to understand so retrieval becomes more accurate.
5. CRAG - Corrective RAG
Corrective RAG (CRAG) is an advanced RAG pipeline designed to solve one of the biggest problems in Retrieval-Augmented Generation:
RAG often retrieves irrelevant chunks, and the AI model generates the wrong answer because the context was wrong not because the model was bad.
CRAG = RAG + Query Rewriting + Chunk Validation + Context Correction
CRAG fixes this by adding multiple correction layers before the final answer is generated.
This diagram shows three important improvements:
- Query Rewriting
- Embedding-based Chunk Validation
- Refined Query Rewriting (second pass)
Together, these steps clean the user query, check the retrieved chunks, remove irrelevant ones, and rebuild a better context for generation.
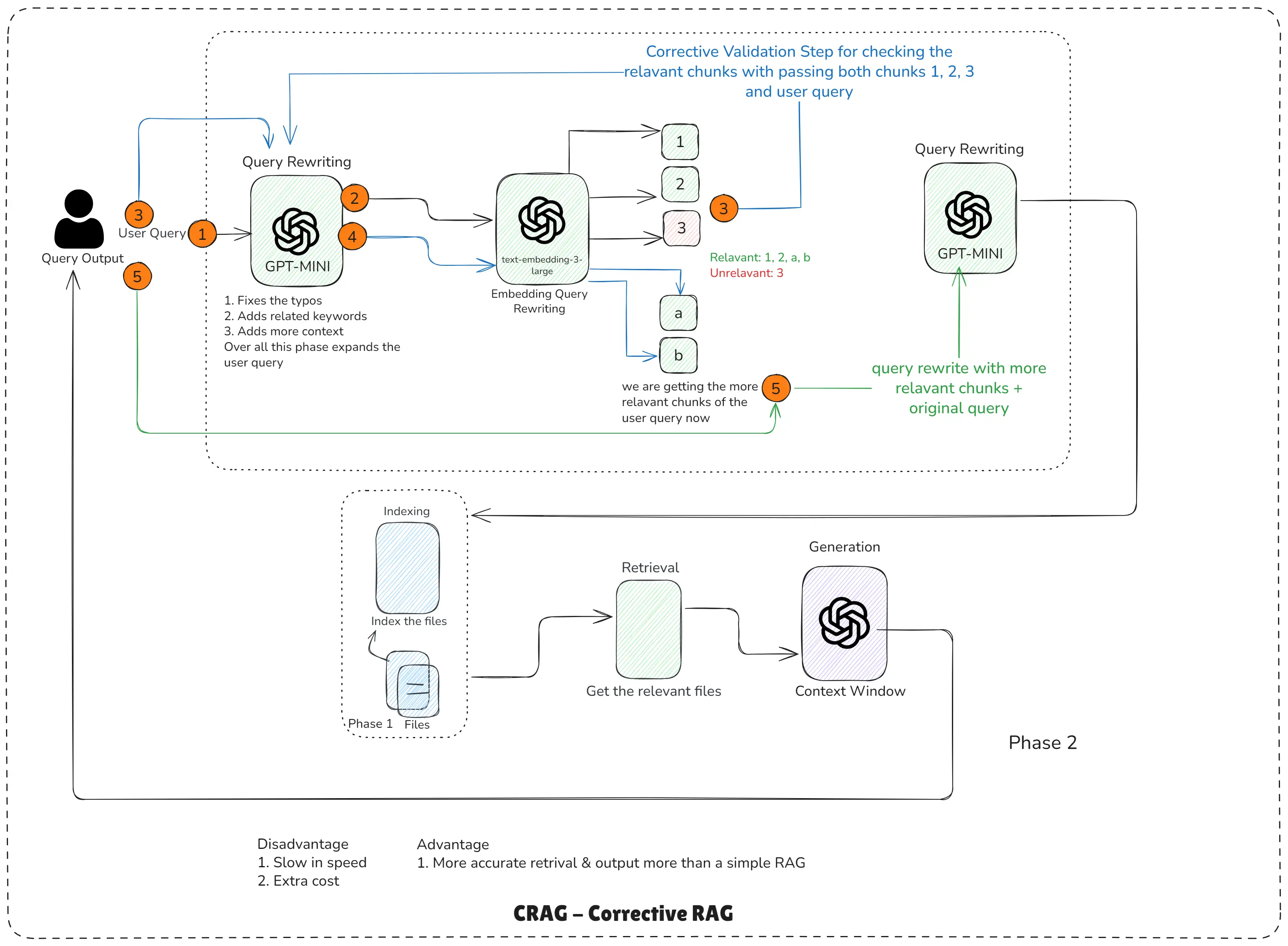
CRAG - Corrective RAG
How CRAG Works?
This RAG pipeline work flow is step-by-step according to the diagram.
Step 1: User asks a query
The pipeline begins with a normal user question, which may contain:
- typos
- missing context
- vague phrasing
Step 2: First Query Rewriting (GPT-MINI)
The first rewriting improves the question by:
- fixing typos
- adding related keywords
- expanding missing context
This makes the query more “search-friendly.”
The goal is to give the retrieval system a cleaner, richer query.
Step 3: Initial Retrieval Happens
Now retrieval pulls chunks from the vector database based on the rewritten query.
But… retrieval is not always perfect.
You may get:
- Relevant chunk A
- Irrelevant chunk B
- Unrelated chunk C
This is the normal weakness of standard RAG.
Step 4: Corrective Validation Step (CRAG’s Superpower)
This is where CRAG becomes smarter than basic RAG.
A small LLM checks each retrieved chunk against:
- The rewritten query
- The original user query
It labels the chunks like:
- Relevant
- Poor match
- Unrelated
This step automatically filters out wrong or weak chunks before they reach the final model.
The goal is to make sure the final context only contains correct information.
Step 5: Embedding Query Rewriting
The system now combines:
- The validated relevant chunks
- The original query
Then it generates a second rewritten query, this time with:
- Improved context
- Correct terminology
- Accurate keyword expansion
This rewritten query is now far more aligned with what the user actually wanted.
Step 6: Final Retrieval + Final Generation
The refined query returns a much cleaner set of chunks.
These chunks enter the context window of the main LLM (GPT-4, Claude, Llama, etc.), which generates the final answer.
The output is now:
- More accurate
- More grounded
- Less hallucinated
Why CRAG Is Needed?
Suppose you are a lawyer, and you get a case under Section 420. But this case also relates to the Criminal Act. So, obviously, you need files for both Section 420 and Criminal Act.
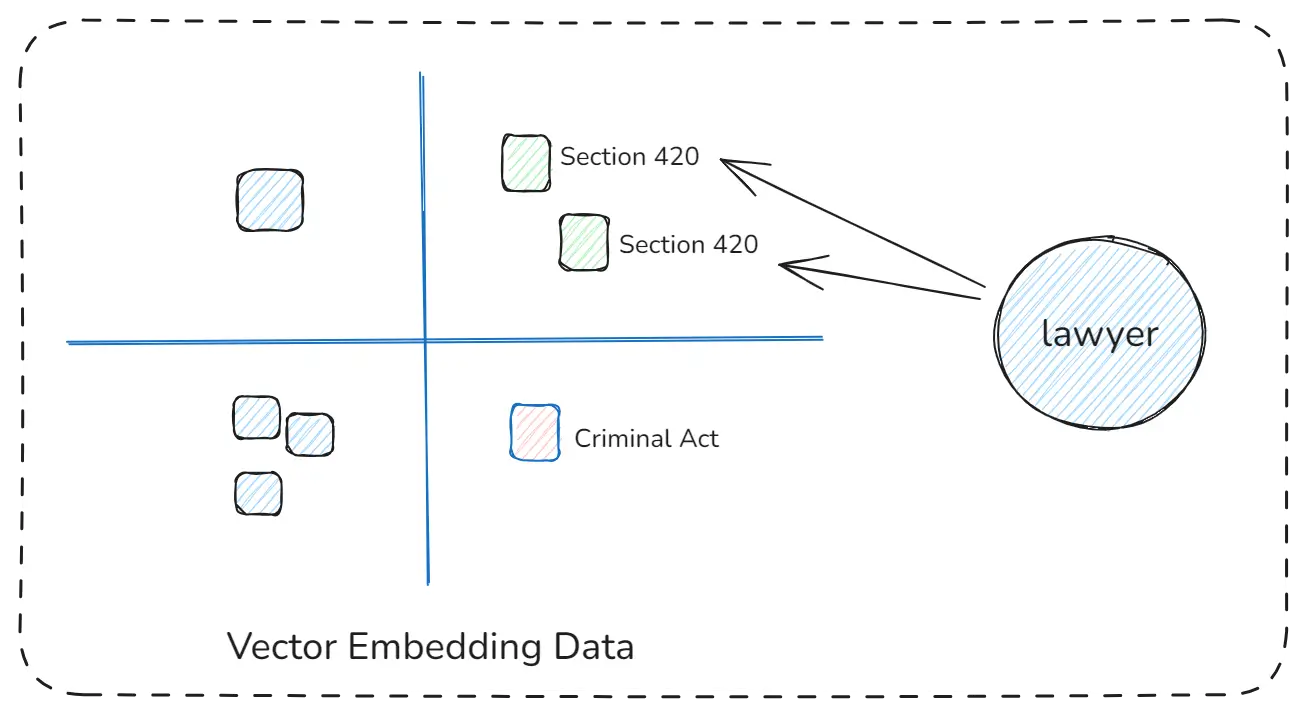
CRAG Vector Embedding Data
Problem: Your RAG system only gives you data for Section 420
- Maybe because you don’t know the connection
- Or you didn’t ask correctly
- Even though the Criminal Act file is already indexed.
Question: How can we solve this problem so the system gives you both Section 420 & Criminal Act files automatically?
Answere: CRAG
CRAG is the best approach when accuracy matters deeply especially in legal, medical, enterprise, and policy-based systems.
6. Ranking in RAG
Even after fixing the user query with Query Rewriting or validating chunks through CRAG, we still face one major challenge:
The retrieval step can return multiple chunks, but not all of them are equally useful.
Some chunks may be:
- Partially relevant
- Outdated
- Duplicates
- Noisy
- Weak matches
If we directly pass all chunks to the LLM, we increase:
- Confusion
- Hallucinations
- Token usage
- Cost
This is where Ranking becomes essential.
Ranking ensures the best retrieved chunks reach the LLM, improving clarity, grounding, and final answer quality.
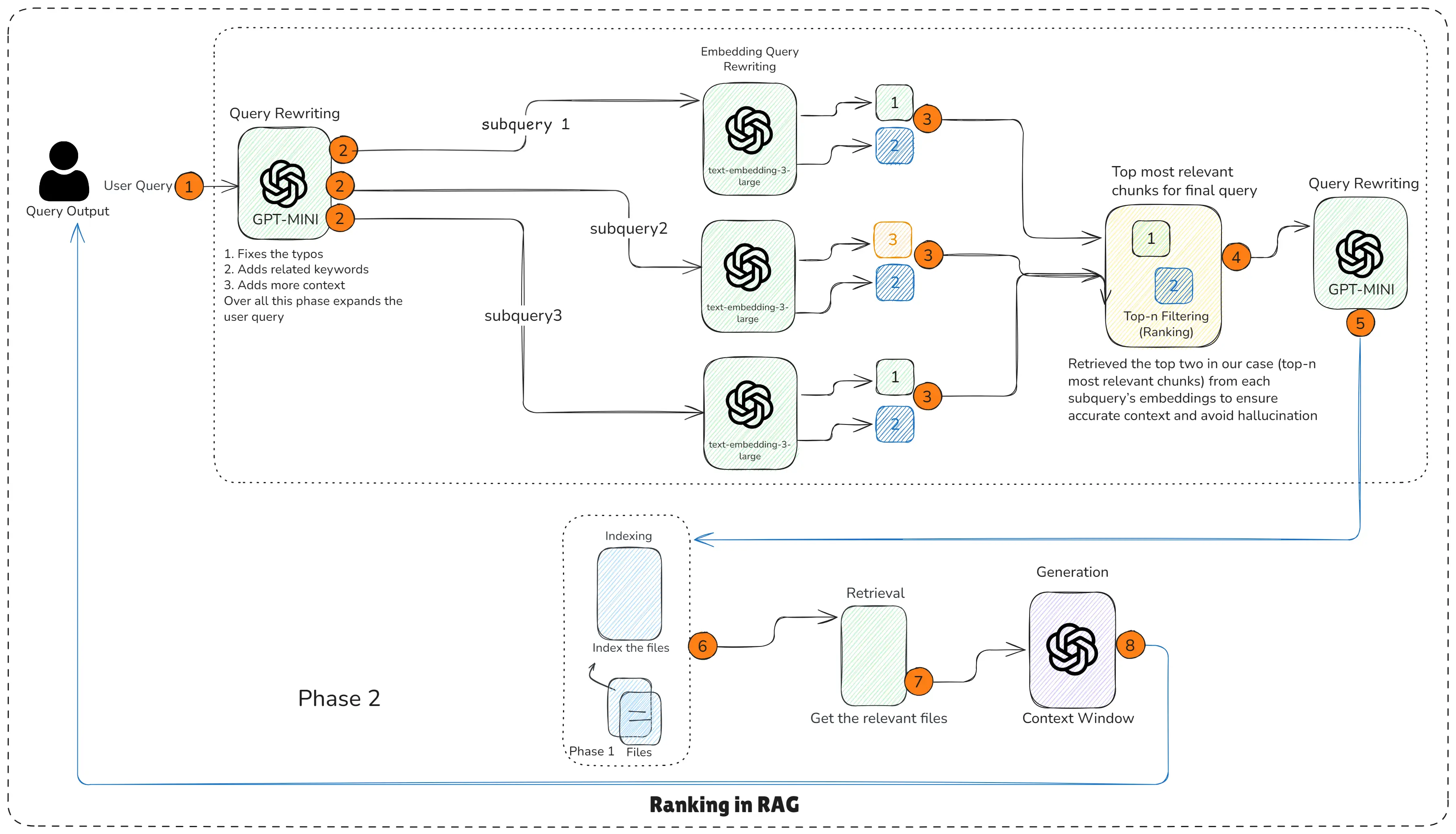
Ranking in RAG
How Ranking Works?
This RAG pipeline work flow is step-by-step according to the diagram.
Step 1: Query Rewriting - Creates subqueries
The rewritten query expands into multiple subqueries (1, 2, 3).
Each subquery focuses on a different aspect of the question.
Step 2: Subqueries - Embedding Models Search for Chunks
Each subquery triggers embedding search:
- Subquery 1 retrieves its top chunks
- Subquery 2 retrieves its top chunks
- Subquery 3 retrieves its top chunks
These chunks receive relevance scores (1, 2, 3…).
Step 3: Ranking Layer - Top-n Filtering
A ranking filter combines the retrieved chunks and selects only the best scoring ones.
In your diagram:
- Top 2 chunks from each subquery are picked
- This ensures accuracy and reduces noise
Step 4: Final Query Rewriting (optional)
A small LLM refines the final query by using:
- selected chunks
- user query
This step enhances alignment and context.
Step 5: Final RAG Flow - Retrieval & Generation
The final top-ranked chunks go into:
- Retrieval
- LLM context window
- Final answer generation
Result: Cleaner context = better grounding = more accurate answer.
Why Ranking Is Needed Even If You Already Use Query Rewriting or CRAG
Many developers assume:
- “If we rewrite the query, retrieval will be perfect.”
- “If we filter chunks with CRAG, accuracy is solved.”
But in real world datasets:
- There are multiple relevant sections
- Some chunks overlap
- Some chunks are slightly relevant but weak
- Some chunks have noise
So even after Query Rewriting or CRAG, you still need Ranking to:
- Pick the strongest evidence
- Prioritize the best context
- Reduce overloading the LLM
- Avoid hallucination caused by noisy chunks
Important: Ranking is NOT a replacement for Query Rewriting or CRAG. It is an additional layer that makes them even more accurate.
Ranking is the step that ensures:
- Only the best retrieved documents reach the LLM
- Noise is removed
- Hallucination is reduced
- Context is more accurate
- Token usage is lower
- Final answers are higher quality
Even if you already use Query Rewriting or CRAG, adding ranking makes your RAG pipeline far more reliable.
7. HyDE RAG - Hypothetical Document Embedding RAG
HyDE is one of the smartest and most creative techniques in advanced RAG systems.
It solves a big problem:
Sometimes the user’s query is too weak, too short, or too vague to retrieve the correct document.
Instead of relying only on the user query, HyDE generates a hypothetical answer first, and uses that answer to find the actual relevant documents from the database.
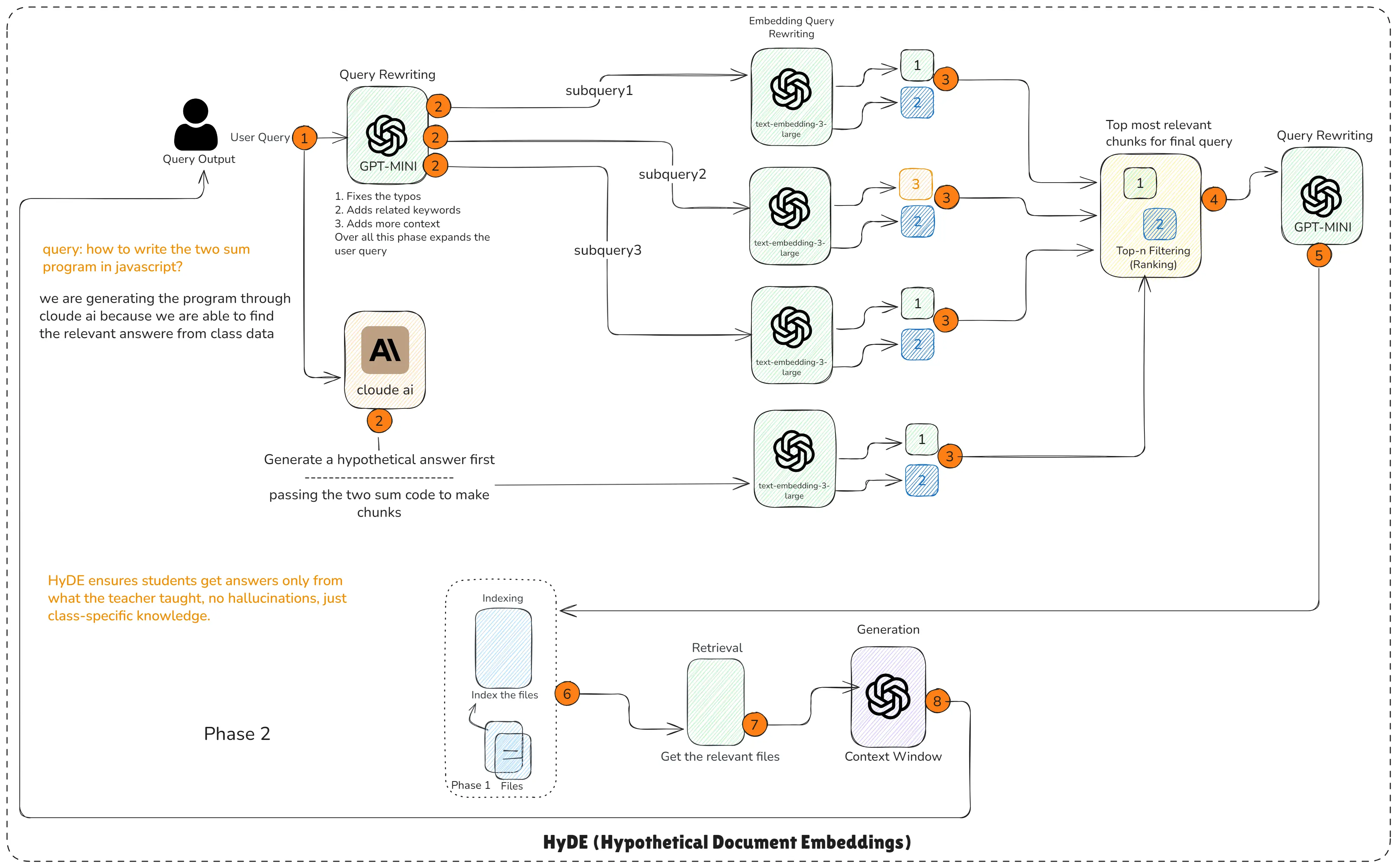
HyDE RAG (Hypothetical Document Embedding)
How HyDE Works?
This RAG pipeline work flow is step-by-step according to the diagram.
Step 1: User asks the question
The student says:
“How to write the two sum program in JavaScript?”This query alone may not retrieve the correct class notes.
Step 2: Query Rewriting
A small LLM (GPT-MINI) cleans the query:
- Fixes typos
- Adds keywords
- Expands missing context
It produces subqueries:
- Subquery 1
- Subquery 2
- Subquery 3
These help in creating better search signals.
Step 3: Generate a Hypothetical Answer (HyDE Step)
This is the special part.
A model like Cloude AI generates a hypothetical answer to the question:
- A sample two-sum solution
- With the structure of a real answer
- But not the final answer
This hypothetical code is used as a semantic anchor.
The goal is not to show this to the student. Instead, the goal is to use it to retrieve the correct chunk from the class notes.
Step 4: Convert Hypothetical Answer into Embeddings
The hypothetical answer is chunked and converted into embeddings.
Why?
Because embeddings created from a correct style of answer help retrieve:
- The exact place in the notes
- The teacher’s original explanation
- The matching code snippet
Much better than using only the student’s question.
Step 5: Retrieve Relevant Chunks for Each Subquery
For each subquery, the embedding model retrieves multiple chunks.
Each chunk is scored:
- Relevant (1)
- Moderate (3)
- Weak (5)
This ensures we see which class-notes chunks are the best match.
Step 6: Ranking (Top-n Filtering)
The ranking layer selects:
- The best chunk from each subquery
- In your example, top 2 chunks are chosen
This filters:
- Noise
- Irrelevant sentences
- Generalized internet examples
Only the most accurate teacher-specific chunks remain.
Step 7: Final Query Rewriting (Clean Context for LLM)
A second rewriting step ensures the LLM receives:
- The final improved query
- The best ranked chunks
This helps avoid hallucinations and ensures precision.
Step 8: Final RAG Generation
The LLM now generates the final answer using:
- Teacher’s actual explanation
- Class notes
- Relevant code taught in class
This ensures students get the exact answer taught in class, not random internet versions.
Why HyDE Is Useful (Real Classroom Example)
This diagram gives a perfect real-world scenario:
Suppose you are building a RAG system for a teacher or academy.
Students ask doubts like:
“How to write the Two Sum program in JavaScript?”But each teacher explains it in their own unique way.
You don’t want the AI to generate:
- A LeetCode style answer
- An advanced optimized answer
- A generalized answer from the internet
You want the AI to return exactly the method the teacher taught in class, nothing extra, nothing less. This is where HyDE becomes powerful.
HyDE (Hypothetical Document Embeddings) improves RAG by:
- Generating a hypothetical answer first
- Turning that answer into embeddings
- Using those embeddings to retrieve the exact real document from the database
It is one of the most effective strategies for:
- Education AI
- Skill training
- Company documentation
- Domain-specific assistants
Because it ensures answers come strictly from the real class or company documents, not hallucinations or random internet text.
Conclusion
Advanced RAG goes far beyond simple retrieval. By adding techniques like Query Rewriting, CRAG, Ranking, and HyDE, we transform a basic RAG pipeline into a highly accurate, reliable, and context-aware system. Each method fixes a real weakness in traditional RAG—whether it's poor queries, bad retrieval, irrelevant chunks, or vague user input.
With these advanced patterns, your RAG pipeline becomes smarter, cleaner, and far more aligned with real-world needs. Whether you're building AI for education, legal work, enterprise knowledge bases, or technical documentation, these techniques ensure higher accuracy, fewer hallucinations, and consistently trustworthy answers.
You now understand how modern RAG systems are designed and are ready to build production-grade RAG pipelines that deliver meaningful, reliable results.
Happy Building with Advanced RAG!